1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
| #include <stdio.h>
#include <stdlib.h>
#define m 12 //散列表表长
#define NULLKEY -1 //单元为空的标记
typedef struct //散列表结点类型
{
int *elem; //数据元素存储基地址,动态分配数组
int count; //当前数据元素个数
}HashTable;
int InitHashTable(HashTable *h) //初始化散列表
{
int i;
h->elem = (int *)malloc(sizeof(int) * m );
h->count=0;
if(h->elem == NULL)
{
printf("分配内存失败\n");
exit(-1);
}
for(i = 0; i < m; i++)
{
h->elem[i] = NULLKEY;
}
return 1;
}
int Hash(int key) //散列函数
{
return key % m; //除留余数法
}
void InsertHash(HashTable *h, int key) //将关键字插入散列表
{
int addr = Hash(key); //求散列地址
while(h->elem[addr] != NULLKEY) //如果不为空,则冲突
{
addr = (addr + 1) % m; //线性探测
}
h->elem[addr] = key; //直到有空位后插入关键字
h->count++;
}
int SearchHash(HashTable h, int key) //散列表查找关键字
{
int addr = Hash(key); //求散列地址
if(h.elem[addr]==NULLKEY) return -1; //如果为空,则元素不存在
else if(h.elem[addr] == key)
return addr; //如果单元中的关键字为key,则查找成功
else{
int i=0;
for(i=1;i<m;i++) {
addr = (addr + 1) % m; //线性探测
if(h.elem[addr] == NULLKEY)
return -1;
else if(h.elem[addr] == key)
return addr;
}
}
return -1;
}
int main()
{
int i=0;
HashTable h;
InitHashTable(&h); //初始化Hash表
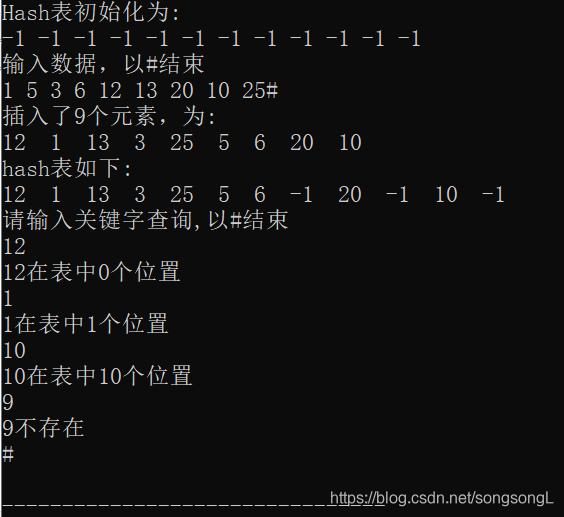
printf("Hash表初始化为:\n");
for(i = 0; i < m; i++)
{
printf("%d ", h.elem[i]);
}
printf("\n");
printf("输入数据,以#结束\n");
while(scanf("%d", &i))
{
if(i == '#') break;
InsertHash(&h,i);
if(h.count >= m)
{
printf("Hash表已满,自动退出插入\n");
break;
}
}
printf("插入了%d个元素,为:\n",h.count);
for(i = 0; i < m; i++)
{
if(h.elem[i]==-1) continue;
else printf("%d ", h.elem[i]);
}
printf("\n");
printf("hash表如下:\n");
for(i = 0; i < m; i++)
{
printf("%d ", h.elem[i]);
}
printf("\n");
printf("请输入关键字查询,以#结束\n");
int key;
scanf("%*[^\n]%*c"); //清空缓存区
while(scanf("%d",&key))
{
if(key == '#') break;
if(SearchHash(h, key)==-1)
printf("%d不存在\n",key);
else printf("%d在表中%d个位置\n",key,SearchHash(h, key));
}
return 0;
}
|