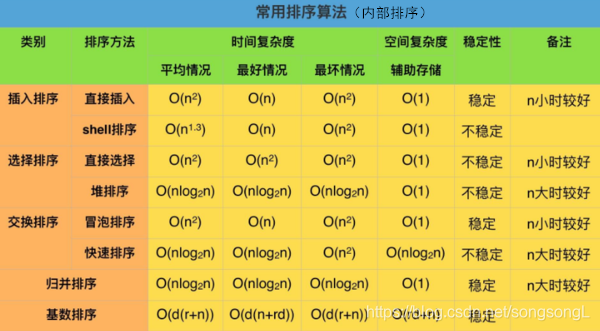
排序的基本概念


快速记忆不稳定排序有哪些:快(快速排序)些(希尔排序)选(选择排序)一堆(堆排序)美女
冒泡排序(Bubble Sort)
思想: 两两比较相邻关键字,及时交换。
*过程:*** 每一趟沉淀一个最大的数。整个过程就像水泡的浮起过程,故因此而得名。
*实现代码:***
1 | void BubbleSort1(int a[],int n){//冒泡排序 |
运行结果:

上述代码有一点问题,就是如果某一趟没有发生任何关键字的交换(说明关键字已经有序了),这时就不在需要再继续去比较了。
改进后的冒泡排序:
1 | void BubbleSort2(int a[],int n){//改进的冒泡排序 |
运行结果:

算法分析:
最好情况(正序):
只需一趟排序,比较n-1次且不移动记录。
最坏情况(逆序):
需n-1趟排序。每一趟比较n-1,n-2,…1次,等差数列,每次交换移动3次记录。
总的比较次数 KCN=n(n-1)/ 2
总的移动次数 RMN=3n(n-1)/ 2
平均情况下:
比较次数: (n-1)(n+2)/4 ,约为 n^2^/4
移动次数: 3n(n-1)/4,约为 3n^2^/4
时间复杂度:O(n^2^)
空间复杂度: O(1)
算法特点:
- 是稳定排序
- 可用于链式存储结构
- 当初始记录无序,n比较大时,此算法不宜采用。
快速排序(Quick Sort)
思想: 选取一个关键字作为分界点,右边的值都比它大,左边值都比它小。左右的 数据可以独立的排序。这是一个递归定义。
*过程:*** 每一趟将数据分为两部分,左小右大,直至low==high。
*实现代码:***
1 | int Partition(int a[],int low,int high){ |
1 | void QuickSort(int r[],int low,int high){ |
运行结果: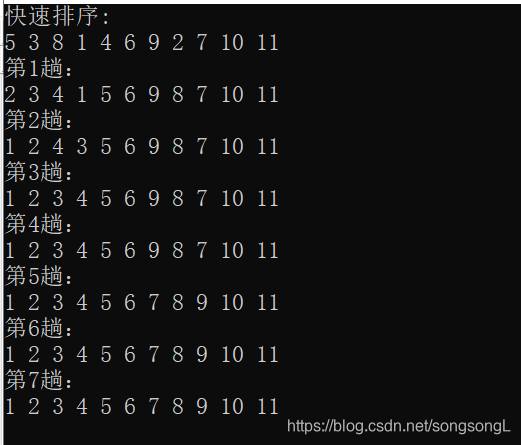
上述代码有一点问题,就是选取第一个或者最后一个元素作为基准,这样在数组已经有序的情况下,每次划分将得到最坏的结果。
一种比较常见的优化方法是随机化算法,即随机选取一个元素作为基准。这种情况下最坏情况不再依赖于输入数据,而是由随机函数决定。实际上,随机化快速排序得到理论最坏情况的可能性仅为 1/(2n)。
改进后的快速排序:
1 | void QuickSort(int array[],int low,int high){ |
运行结果: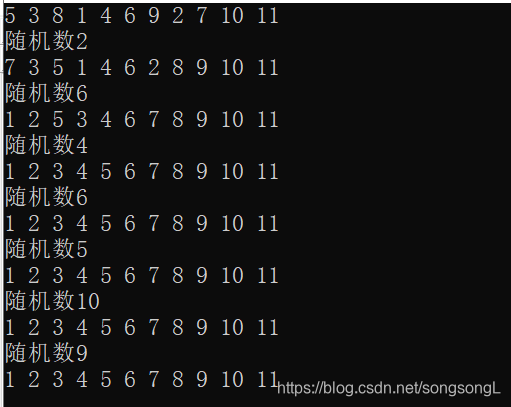
算法分析:
最好情况:
每一次分割都是长度大致相等的子表
最坏情况(有序):
每一次分割只能得到比上一次记录少一个的子序列。
平均时间复杂度:O(nlog2n)
空间复杂度: 最好O(log2n)、最差O(n)
算法特点:
- 是不稳定排序
- 很难于链式存储结构
- 当初始记录无序,n比较大时,此算法宜采用。
直接插入排序(Straight Insertion Sort)
思想: 与怕扑克牌一样,拿起一张牌,插入合适位置。
*过程:*** 每一趟将一个待排序记录插入到适当位置。
*实现代码:***
1 | void InsertSort(int r[],int n){//第0位置设置观察哨,第1位置为有序区,从第二个开始扫描插入 |
运行结果:

红线左边的是作为观察哨用的,也就是数组中第0位置被设为观察哨。
算法分析:
最好情况(正序):
每一趟排序,比较1次且不移动。
最坏情况(逆序):
每一趟排序。比较i次,移动i+1次。
整个过程(需执行n-1趟):
最好情况,比较n-1次且不移动记录。
最坏情况,每一趟比较2,3,…,n,等差数列。移动3,4,…n+1次,等差数列。
总的比较次数 KCN=(n-1)(n+2)/ 2
总的移动次数 RMN=(n+4)(n-1)/ 2
平均情况下:
比较次数: (n-1)(n+4)/4 ,约为 n^2^/4
移动次数: (n+4)(n-1)/4,约为 n^2^/4
时间复杂度:O(n^2^)
空间复杂度: O(1)
算法特点:
- 是稳定排序
- 可用于链式存储结构
- 当初始记录无序,n比较大时,此算法不宜采用。
折半插入排序(Binary Insertion Sort)
与直接插入排序区别不大,直接插入排序是以顺序查找方式找插入位置,这里只是将其换为折半查找方式来找插入位置。
实现代码:
1 | void BInsertSort(int Array[],int n) // 折半插入排序升序排列 |
运行结果与直接插入排序一样
算法分析:
平均情况下,折半查找比顺序查找快,但移动次数不变。
时间复杂度:O(n^2^)
空间复杂度: O(1)
算法特点:
- 是稳定排序
- 不可用于链式存储结构
- 适合初始记录无序,n比较大时。
希尔排序(Shell’s Sort)
思想: 通过 增量 将整个待排序列分割成几组,对每组分别进行直接插入排序。然后改变增量,重新分组,增加每组的数据量。直到所取增量为1,所有记录在同一组中进行直接插入排序。
*过程:*** 每一趟分组排序,使得整个待排序列趋于 *“基本有序”。*** 最后在一个组中直接插入排序的时候效率高。
实现代码:
1 | void ShellInsertSort(int a[], int n) //希尔排序 |
运行结果: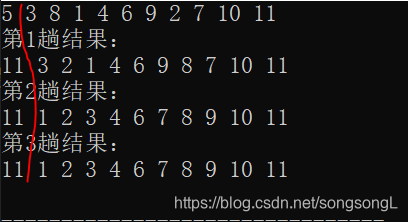
算法分析:
增量大于1时,关键字是跳跃移动的,最后一趟只需做少量比较和移动即可完成排序。
时间复杂度:O(n^1.3^)
空间复杂度: O(1)
算法特点:
- 是不稳定排序
- 不可用于链式存储结构
- 适合初始记录无序,n比较大时。
简单选择排序(Simple Selection Sort)
也叫直接选择排序
思想: 每一趟选择待排记录中关键字最小的记录。
*过程:*** 经过n-1趟,排序完成。
*实现代码:***
1 | void SelectionSort(int a[], int n) { //直接选择排序 |
运行结果:

算法分析:
最好情况(正序):不移动记录。
最坏情况(逆序):移动3(n-1)次记录。
无论如何,比较次数均为: KCN=n(n-1)/ 2
时间复杂度:O(n^2^)
空间复杂度: O(1)
算法特点:
- 是不稳定排序
- 可用于链式存储结构
- 适用于每一记录占用空间较多,移动次数较少。
堆排序(Heap Sort)
什么是堆:
n个元素的序列{k1,k2,…,kn},满足:
*ki>=k2i 且 ki>=k2i+1***
或 *ki<=k2i 且 ki<=k2i+1***
称之为 堆
将待排数组记录看成是一棵完全二叉树的顺序存储结构,则堆实质上是满足如下性质的完全二叉树:
树中所有非终端结点的值均不大于(或不小于)其左右孩子结点的值
对应大根堆与小根堆。
思想: 利用大根堆(或小根堆)堆顶记录的关键字最大(或最小)这一特征,每次都选择堆的堆顶。
**过程:** 每拿走一个堆顶(把堆顶记录与最后一个记录交换),重新调整为堆,继续拿。
实现代码:
调整堆:
1 | void heapAdjust(int a[], int i, int nLength) //调整堆 |
建初堆:
在完全二叉树中,所有序号大于⌊n/2⌋ 的结点都是叶子,以这些结点为根的子树已是堆,不用调整。
1 |
|
堆排序:
1 | void HeapSort(int a[],int length) // 堆排序 |
运行结果:

算法分析:
时间复杂度:O(nlog2n)
空间复杂度: O(1)
算法特点:
- 是不稳定排序
- 不可用于链式存储结构
- 数据较多时较为高效。
归并排序(Merging Sort)
思想: 将两个或两个以上的有序表合并成一个有序表。
**过程:** 初始序列可看成是n个有序的子序列,每个字序列长度为1,然后两两归并,重复,直到得到长度为n的有序序列为止。
实现代码:
1 | void Merge(int r[],int r1[],int s,int m,int t){//归并 |
运行结果: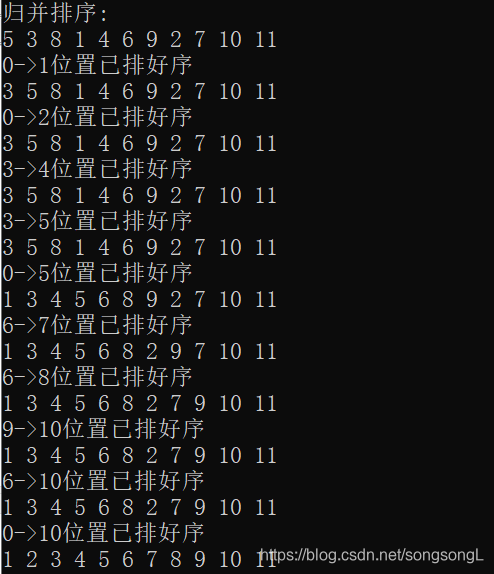
算法分析:
时间复杂度:O(nlog2n)
空间复杂度: O(n)
算法特点:
- 是稳定排序
- 可用于链式存储结构
基数排序(Radix Sort)
它是和前面所述各类排序方法完全不同的一种排序方法。前面的各类排序方法都是建立在关键字比较的基础上的,而基数排序不比较关键字的大小,是一种借助于多关键字排序的思想对单关键字排序的方法。
怎么理解呢?
以扑克牌为例,扑克牌由面值和花色构成(多关键字),要对这副牌进行排序有两种策略(**以花色大于面值,且红桃>黑桃>梅话>方块来说明**):
最高位优先法(MSD(Most significant digital))
先将牌按花色分为四堆,然后每一堆按面值进行排序。



这样,这副牌就按从小到大顺序排好了。最低位优先法(LSD(Least significant digital))
这是一种“分配”与“收集”交替进行的方法。
先将牌按面值分成13堆(完整的牌),从小到大收集起来,再把花色一样的放在一起即可。



这样,这副牌就按从小到大顺序排好了。
基数排序思想: 一个关键字可以看成是“多个关键字”组成,个位、十位、百位等,从而借助于多关键字排序对单关键字排序。
*过程:*** 从低位到高位,将值相同的收集起来放在一个队里。再分配,再收集,最终完成排序

*实现代码:***
1 | int getNumInPos(int num,int pos) //获得某个数字的第pos位的值 |
运行结果:
算法分析:
对于n个记录,假设每个记录含d个关键字,每个关键字的取值范围为rd个值,每一趟分配的时间复杂度为 O(n) ,每一趟收集的时间复杂度为 O(rd) 。整个排序需进行d趟分配与收集。
*时间复杂度:O(d(n+rd))***
*空间复杂度: O(n+rd)***
算法特点:
- 是稳定排序
- 可用于链式存储结构
- 时间复杂度能突破基于关键字比较方法的下界 O(nlog
2n)。 达到 O(n)。
总的代码:
1 | #include<iostream> |